El análisis de correspondencias, caso especial del análisis de componentes principales, se puede considerar como una técnica reductiva donde el objetivo del investigador es reconocer las relaciones entre dos conjuntos de categorías. A diferencia del análisis factorial de componentes principales, el análisis de correspondencias trata de “analizar las formas que adoptan las relaciones entre las variables”. Se busca realizar un análisis geométrico de las relaciones, de ahí la importancia que en este análisis tiene la representación gráfica, típicamente conocida como mapa de posicionamiento o mapping de atributos y marcas.
Muy utilizado en la práctica para representar mapas de posicionamiento (mapping) de elementos cruzados para realizar análisis de asociación. El típico ejemplo de marcas / atributos con la presencia del ideal, puede ser resuelto con este análisis.
Uno de sus puntos fuertes, es la posibilidad de realizarlo a partir de datos elaborados, es decir, a partir de una matriz creada ad-hoc para ello. El caso que presentamos es de este tipo.
El análisis de correspondencias no es una técnica muy exigente con las propiedades estadísticas que deben cumplir los datos. El uso de variables cualitativas, particularmente escalas nominales en su forma más simple (tablas de contingencia) hace que sea igualmente adecuado para establecer relaciones lineales como no lineales. El hecho de que no haya que tener precauciones con las hipótesis estadísticas, no quiere decir que no haya que ser cuidadoso con otras consideraciones. Fundamentalmente, hay que asegurarse de que los poseedores de los atributos son comparables respecto a esos atributos. (Aldás, 2000)
El análisis permite representar simultáneamente dos conjuntos de variables en un mismo espacio tratando de representar la mayor parte de la información contenida en una matriz de números positivos, “para ello se fija no en los valores absolutos, sino en las correspondencias entre las características, es decir, en los valores relativos” (Pedret, Sagnier y Camps, 2000).
El análisis de correspondencias se basa en una transformación de la prueba c. En esencia, esta prueba plantea la hipótesis nula de que la distribución de las frecuencias en la tabla de contingencia es homogénea, es decir, que no hay marcas que hayan recibido una mayor cantidad de asociaciones con un atributo determinado que otros, siendo una variable independiente de la otra. Si esta hipótesis nula pudiera rechazarse, se disponen de diversas medidas que permiten cuantificar el grado de dependencia. Podemos rechazar la hipótesis nula, de tal forma que afirmamos la existencia de unas marcas más identificadas con unos atributos que otras, por lo que tiene sentido intentar analizar en qué consisten las similitudes y diferencias de las categorías de unas variables respecto a otras.
Perfiles de fila y columna |
El perfil es un vector que contiene las frecuencias relativas de cada fila o columna. Resultado del cociente entre la celda y su total fila o columna. En BarbWin son los porcentajes verticales y horizontales en el análisis. Son utilizados para calcular la distancia entre todas las categorías. |
|---|---|
Distancia |
Operación realizada para obtener una medición de la separación o cercanía entre las categorías analizadas, se utiliza la distancia c². |
Masa |
Representa el peso de cada categoría de fila o columna sobre el total de la muestra, es decir, porcentajes totales de categoría. |
Valor propio o inercia |
Resultado de operar la masa con la distancia, es el indicativo del peso que tendrá cada variable original en las dimensiones finales. |
Contribuciones absolutas |
Indica el peso que cada categoría de fila o columna (de forma independiente) tiene en el total de la dimensión. |
Contribuciones relativas |
Indican el peso de cada dimensión en cada categoría de fila y columna. |
Distancia al centroide (baricentro) |
Medida de la separación de cada categoría del centro del la representación gráfica. |
Proceso de cálculo
Este análisis se puede realizar a partir de tablas de contingencia calculadas a partir de una matriz de individuos por variables (típico fichero de entrevistas) con datos en frecuencias o también a partir de porcentajes, sumas y medias. En este caso, en el diálogo correspondiente al análisis de correspondencias, deberemos señalizar que variable/s pasan a ser categorías de columna, y cuáles pasan a ser categorías de fila. En principio si trabajamos con frecuencias o porcentajes es indiferente, pero si trabajamos con medias o sumas, las variables métricas de las que se calcula el estadístico deben ser situadas en filas.
| • | Columnas, caja donde se establecen las variables cuyas categorías serán consideradas puntos columna |
| • | Filas, caja donde se establecen las variables cuyas categorías serán consideradas puntos fila |
| • | Eliminar columnas / filas con menos de..., si alguna columna o fila en el análisis presenta una frecuencia marginal (sólo activo con frecuencias) inferior a n casos, se eliminará esa fila o columna del análisis, reduciendo la base total de cálculo. |
| • | Mostrar tabulación, muestra la matriz de entrada del análisis si proviene de una tabla de contingencia. |
| • | Salida a rejilla, muestra los resultados básicos del análisis junto con el mapa gráficos. |
| • | Representación gráfica, muestra el mapa gráfico con las dos dimensiones principales. El usuario tiene opción posteriormente a combinar otras dimensiones entre sí. |
| • | Los datos de fila serán, permite elegir el tipo de dato con el que se realizará el análisis. La última opción fichero actual se comenta a continuación. |
También se puede realizar el análisis a partir de una entrada especial que sea una tabla de contingencia introducida como fichero de datos. Esta es la forma más sencilla de trabajo. El fichero de datos constará de una primera variable de tipo alfanumérico donde se escribirán los atributos o las marcas, y una serie de variables métricas que se corresponderán con las marcas / atributos analizados.
Pongamos en práctica un ejemplo y comentemos sus resultados.
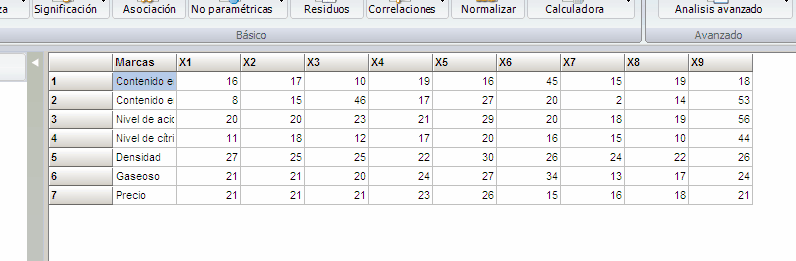
Fichero Datos para correspondencias simple.gbw
Órdenes Análisis-> Reducción de datos-> Correspondencias simple-> Clic sobre Fichero Actual-> Aceptar
X1 Aquarius
X2 Aquarius New
X3 Aquarius Classic
X4 Gatorade Classic
X5 Gatorade Lemmon
X6 Sprite Sport
X7 Upgrade
X8 Upgrade Lemmon
X9 Upgrade Orange
Matriz de entrada de la tabla de contingencia
El primer resultado que se obtiene tras el cálculo, está relacionado con el objetivo principal de la técnica. Al ser una técnica con carácter reduccional, el objetivo es reducir las dimensiones de forma que se pueda explicar el máximo de la información original en unas nuevas dimensiones, sin perder excesiva información. En esta primera tabla, se muestra los valores propios que deben ser entendidos como magnitudes indicadoras del poder explicativo de cada una de las nuevas dimensiones en las que se estructuran los datos.
Valores propios y porcentaje de varianza
|
Valor propio |
% de varianza |
% acumulado |
Dimensión 1 |
6,251 |
60,06 |
60,06 |
Dimensión 2 |
2,170 |
20,85 |
80,91 |
Dimensión 3 |
1,667 |
16,01 |
96,92 |
Dimensión 4 |
0,020 |
1,9 |
98,82 |
Dimensión 5 |
0,077 |
0,74 |
99,56 |
Dimensión 6 |
0,045 |
0,44 |
100 |
Las dos columnas restantes muestran un indicador de la proporción de varianza que explica cada una de las dimensiones. La varianza explicada es la proporción de valor propio sobre el conjunto de información explicada y la varianza acumulada nos muestra el nivel máximo de información que explicamos.
El número de dimensiones que el análisis calcula está relacionado con el mínimo de filas o columnas que tenga la tabla de contingencia restando una unidad. Si la matriz de entrada tiene J filas y K columnas, el número de dimensiones del análisis será como máximo el mínimo [(J, K)-1].
Al igual que en el análisis de componentes principales, existen varios criterios para determinar cuál es el número óptimo de dimensiones, pero habitualmente se trabaja con aquellas dimensiones que al menos alcancen la unidad (criterio de Káiser-Gutmann) en el valor propio. En nuestro ejemplo podemos observar como a partir de la tercera dimensión cae mucho el valor propio y, por tanto, la varianza explicada.
La segunda tabla de información que aparece, tiene por objetivo mostrar la varianza explicada, pero desde una perspectiva marginal, mediante las aportaciones de cada una de las categorías de fila / columna que intervienen en el análisis. Esta tabla nos muestra de forma conjunta las contribuciones absolutas y las relativas para cada una de las categorías en el análisis.
Contribuciones a la formación de los ejes por las filas
|
Contribuciones Absolutas |
|||||
Variable |
D1 |
D2 |
D3 |
D4 |
D5 |
D6 |
Aquarius |
7,64 |
7,08 |
6,18 |
0,74 |
24,48 |
16,04 |
Aquarius New |
1,3 |
2,93 |
0,21 |
7,61 |
27,51 |
0 |
Aquarius Classic |
22,36 |
11,49 |
34,67 |
6,99 |
7,3 |
0,06 |
Gatorade Classic |
1,26 |
0,23 |
0,43 |
41,17 |
0,32 |
21,57 |
Gatorade Lemmon |
0,54 |
1,8 |
4,42 |
7,52 |
1,84 |
14,38 |
Sprite Sport |
18,28 |
52,18 |
11,51 |
0,17 |
0,42 |
4,4 |
Upgrade |
9,37 |
22,44 |
1,84 |
20,82 |
19,78 |
0 |
Upgrade Lemmon |
2,65 |
0,1 |
1,56 |
14,64 |
15,52 |
43,53 |
Upgrade Orange |
36,61 |
1,74 |
39,18 |
0,34 |
2,82 |
0 |
Suma |
100 |
100 |
100 |
100 |
100 |
100 |
Contribuciones a la formación de los ejes por las columnas
|
Contribuciones Absolutas |
|||||
Variable |
D1 |
D2 |
D3 |
D4 |
D5 |
D6 |
Contenido en sales |
28,34 |
29,24 |
12,56 |
5,01 |
0,05 |
13,21 |
Contenido en azúcar |
50,65 |
26,53 |
5,03 |
0,58 |
2,15 |
0,2 |
Nivel de acidez |
5,09 |
9,93 |
9,73 |
7,87 |
51,12 |
0,29 |
Nivel de cítricos |
2,97 |
11,79 |
34,92 |
9,33 |
28,57 |
0,11 |
Densidad |
5,57 |
7,02 |
12,72 |
31,08 |
12,94 |
18,03 |
Gaseoso |
5,81 |
4,69 |
1,69 |
36,5 |
5,18 |
30,92 |
Precio |
1,57 |
10,79 |
23,35 |
9,64 |
0,23 |
39,35 |
Suma |
100 |
100 |
100 |
100 |
100 |
100 |
Llamamos contribución absoluta de un elemento a la influencia que una categoría ha tenido en la formación de la dimensión factorial. Para cada agrupación categorías de fila y categorías de columna la suma de las cargas es 100 (en vertical).
Calidad de representación de las categorías por las filas
|
Contribuciones relativas |
||||||
|---|---|---|---|---|---|---|---|
Variable |
D1 |
D2 |
D3 |
D4 |
D5 |
D6 |
Suma |
Aquarius |
62,63 |
20,14 |
13,5 |
0,19 |
2,48 |
0,95 |
100 |
Aquarius New |
43,99 |
34,39 |
1,91 |
8,16 |
11,49 |
0 |
100 |
Aquarius Classic |
62,28 |
11,11 |
25,75 |
0,62 |
0,25 |
0 |
100 |
Gatorade Classic |
43 |
2,76 |
3,93 |
44,67 |
0,14 |
5,36 |
100 |
Gatorade Lemmon |
19,88 |
23,07 |
43,45 |
8,8 |
0,84 |
3,85 |
100 |
Sprite Sport |
46,27 |
45,85 |
7,77 |
0,01 |
0,01 |
0,08 |
100 |
Upgrade |
50,49 |
41,99 |
2,64 |
3,56 |
1,32 |
0 |
100 |
Upgrade Lemmon |
65,22 |
0,87 |
10,25 |
11,4 |
4,71 |
7,76 |
100 |
Upgrade Orange |
76,74 |
1,27 |
21,89 |
0,02 |
0,07 |
0 |
100 |
Calidad de representación de las categorías por las filas
|
Contribuciones relativas |
||||||
Variable |
D1 |
D2 |
D3 |
D4 |
D5 |
D6 |
Suma |
Contenido en sales |
67,34 |
24,12 |
7,95 |
0,38 |
0 |
0,23 |
100 |
Contenido en azúcar |
82,7 |
15,04 |
2,19 |
0,03 |
0,04 |
0 |
100 |
Nivel de acidez |
42,37 |
28,7 |
21,61 |
2,08 |
5,26 |
0,02 |
100 |
Nivel de cítricos |
17,44 |
24,04 |
54,68 |
1,74 |
2,07 |
0 |
100 |
Densidad |
44,04 |
19,27 |
26,81 |
7,79 |
1,26 |
1,03 |
100 |
Gaseoso |
62,21 |
17,43 |
4,82 |
12,39 |
0,68 |
2,4 |
100 |
Precio |
12,92 |
30,82 |
51,22 |
2,51 |
0,02 |
2,35 |
100 |
Llamamos contribución relativa de un elemento a la influencia o índice de calidad de cada una de las categorías fila o columna en la dimensión factorial, es decir, la calidad de representación de la categoría en la dimensión.
En la mayoría de las ocasiones sucede que una carga importante de una categoría sobre la formación de eje, es complementada con una muy buena calidad de representación en las dimensiones factoriales analizadas, pero no siempre suele suceder a la inversa.
Masa y distancia en el análisis de correspondencias
Variable |
Masa |
Distancia |
|---|---|---|
Aquarius |
0,09 |
0,08 |
Aquarius New |
0,100 |
0,02 |
Aquarius Classic |
0,114 |
0,2 |
Gatorade Classic |
0,104 |
0,02 |
Gatorade Lemmon |
0,127 |
0,01 |
Sprite Sport |
0,128 |
0,19 |
Upgrade |
0,075 |
0,15 |
Upgrade Lemmon |
0,086 |
0,03 |
Upgrade Orange |
0,176 |
0,17 |
Contenido en sales |
0,127 |
0,21 |
Contenido en azúcar |
0,147 |
0,26 |
Nivel de acidez |
0,164 |
0,05 |
Nivel de cítricos |
0,118 |
0,09 |
Densidad |
0,165 |
0,05 |
Gaseoso |
0,146 |
0,04 |
Precio |
0,132 |
0,06 |
La siguiente tabla que aparece nos muestra tres indicadores relacionados con la ulterior representación gráfica:
| • | Masa o asociaciones de cada categoría de fila o columna sobre el total de las asociaciones realizadas. Esta magnitud es presentada en tanto por uno. |
| • | Distancia, proximidad o lejanía de cada categoría de fila o columna sobre el centro de gravedad del mapa de posicionamiento. Las categorías que presenten una mayor distancia del baricentro o centro de gravedad del mapa, son las que presentan un mayor poder diferenciador entre las categorías. Los atributos cercanos al baricentro no son discriminadores en sus relaciones. |
| • | El tercer indicador es una matriz con las coordenadas de cada categoría de fila o columna en el mapa de posicionamiento obtenido en cada una de las dimensiones factoriales. |
Coordenadas en el mapa de correspondencias
|
Coordenadas en el mapa gráfico |
|||||
|---|---|---|---|---|---|---|
Variable |
D1 |
D2 |
D3 |
D4 |
D5 |
D6 |
Aquarius |
-0,23 |
0,13 |
0,11 |
0,01 |
0,05 |
0,03 |
Aquarius New |
-0,09 |
0,08 |
0,02 |
-0,04 |
-0,05 |
0 |
Aquarius Classic |
0,35 |
-0,15 |
0,23 |
0,03 |
-0,02 |
0 |
Gatorade Classic |
-0,09 |
0,02 |
0,03 |
-0,09 |
0 |
-0,03 |
Gatorade Lemmon |
0,05 |
0,06 |
0,08 |
-0,03 |
0,01 |
0,02 |
Sprite Sport |
-0,3 |
-0,3 |
-0,12 |
0,01 |
-0,01 |
0,01 |
Upgrade |
-0,28 |
0,26 |
-0,06 |
0,07 |
-0,05 |
0 |
Upgrade Lemmon |
-0,14 |
-0,02 |
0,05 |
0,06 |
0,04 |
-0,05 |
Upgrade Orange |
0,36 |
0,05 |
-0,19 |
0,01 |
0,01 |
0 |
Contenido en sales |
-0,37 |
-0,22 |
-0,13 |
0,03 |
0 |
-0,02 |
Contenido en azúcar |
0,46 |
-0,2 |
0,08 |
0,01 |
-0,01 |
0 |
Nivel de acidez |
0,14 |
0,11 |
-0,1 |
0,03 |
0,05 |
0 |
Nivel de cítricos |
0,13 |
0,15 |
-0,22 |
-0,04 |
-0,04 |
0 |
Densidad |
-0,15 |
0,1 |
0,11 |
0,06 |
-0,02 |
0,02 |
Gaseoso |
-0,16 |
-0,08 |
0,04 |
-0,07 |
0,02 |
0,03 |
Precio |
-0,09 |
0,13 |
0,17 |
-0,04 |
0 |
-0,04 |
Por último, se presenta el mapa cartesiano utilizando las dos dimensiones principales.
Mapa de posicionamiento
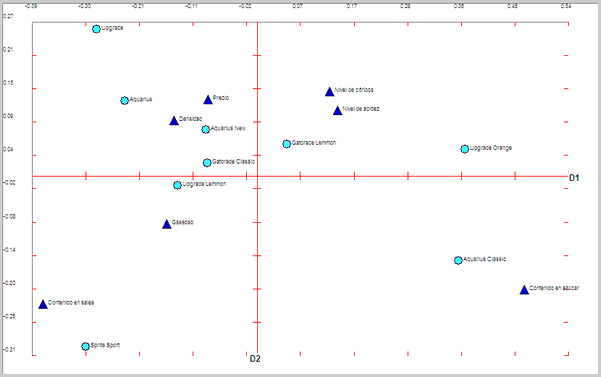
A diferencia de lo que sucede en el análisis de componentes principales, en el análisis de correspondencias si que se puede realizar un análisis de la proximidad entre las categorías de fila y/o columna en el mapa. Siguiendo a Pedret, Sagnier y Camps (2000):
| • | La proximidad entre dos categorías fila o dos categorías columna, implica la existencia de perfiles parecidos, es decir que se producen asociaciones de carácter común o similar, lo que implica un alto nivel de correlación. Si por ejemplo comentáramos los atributos de las marcas, diremos que nivel de acidez y nivel de cítricos son dos atributos considerados muy semejantes en sus relaciones. |
| • | La proximidad al origen implica un comportamiento medio nada diferenciador del resto. Son categorías que no ofrecen diferencias, en definitiva tiene un menor poder descriptivo. |
| • | La proximidad entre categorías de fila y columna nos permite concluir que existe una fuerte asociación entre cada la fila y la columna. |